
Establishing the Contest
The Human Protein Atlas (HPA) is a Swedish program aimed to map the expression of proteins in cells and organs of the human body, and the makers of the Protein Atlas database (www.proteinatlas.org). All the data in this knowledge resource is open access to allow scientists both in academia and industry to freely access the data for exploration of the human proteome. The HPA Cell Atlas aims to capture the subcellular map of the human proteome by doing antibody-based fluorescence imaging with confocal microscopy. Researchers in the HPA have been acquiring protein images for about 15 years, and we have generated profiles for more than 12,000 proteins, or 63% of the protein-coding human genome (doi: 10.1126/science.aal3321). As part of the standard workflow, the protein localizations need to be annotated manually from the generated images.
The HPA Challenge, published on Thanksgiving Day in “Analysis of the Human Protein Atlas Image Classification Competition” in Nature Methods, was inspired by the need to automate the most challenging part of an otherwise automated pipeline, namely to classify localization patterns for proteins in the images from the HPA Cell Atlas. In 2018, the HPA published a citizen science challenge with the same aim through the massive online multiplayer video game named EVE online (doi: 10.1038/nbt.4225). Over 300,000 gamers contributed 33 million classifications, which were incorporated into a learning model to help predict multiple localization patterns.

Our previous efforts for automating the annotation of protein localizations included using citizen science, where gamers participated in annotating HPA images.
The main challenge of this image classification task is the need to assign multiple labels per image, due to the fact that many proteins reside in several cellular compartments simultaneously. Since then, the HPA hosted a competition on the Kaggle platform with the aim to develop computational models for this classification task. Here contestants also had to address the mixed localization patterns and the difficult class imbalance of this dataset, which arises from some classes having millions of images, where others only had a dozen. This can be challenging for machine learning algorithms which typically have hard time to handle rare cases, as a result, it may simply ignore those rare classes. To prevent that, we decided to use macro F1 as the evaluation metric which emphasis equal importance for all the classes.

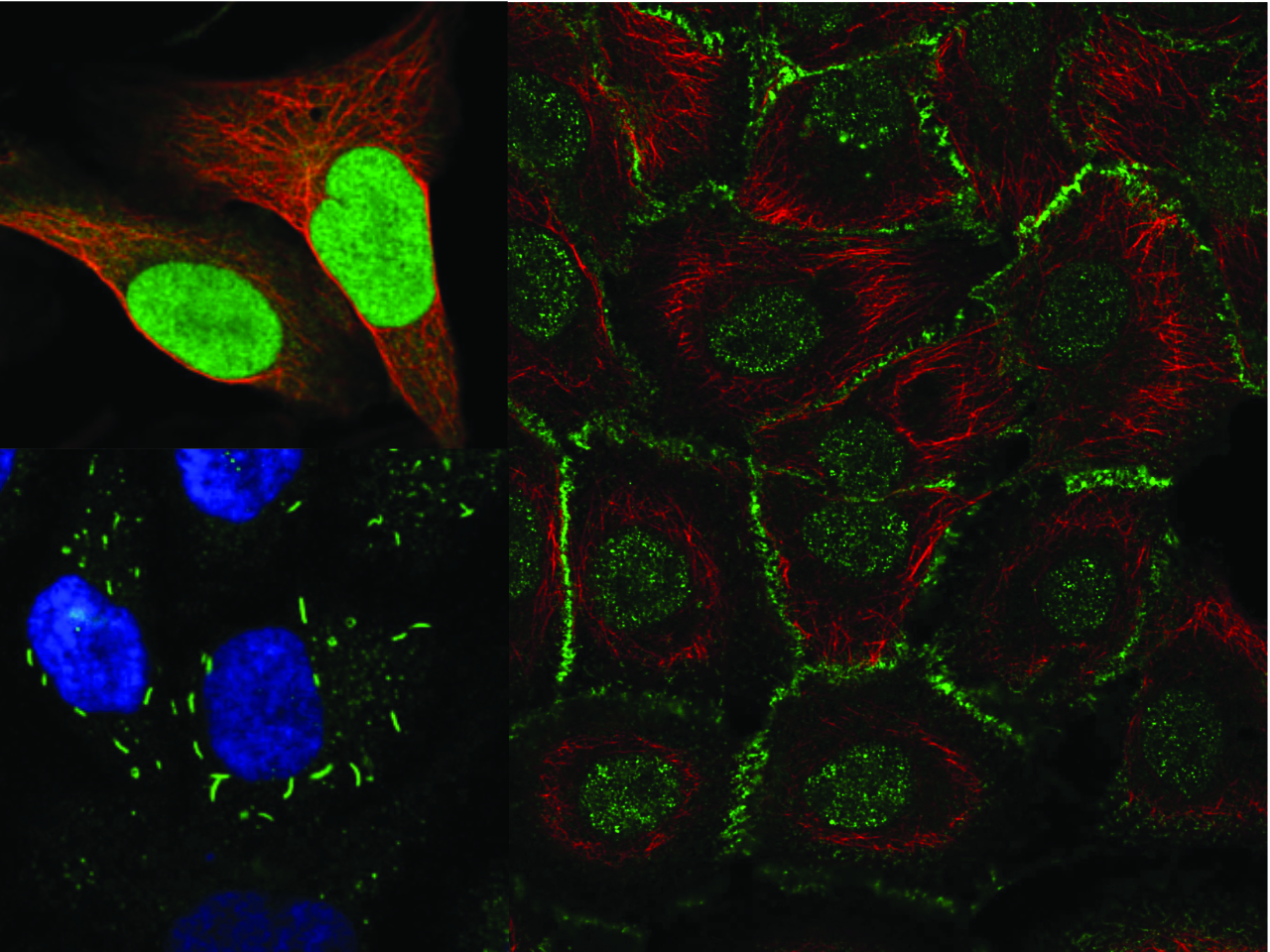
The HPA Protein Atlas Image Classification sought to tackle two main challenges. First, the localization patterns have vastly different frequencies; the most common, Nucleus, and rarest, Rods & Rings, are illustrated here. Second, the participants’ models needed to classify up to 6 localization patterns for each protein to account for multilocalizing proteins.
Besides the evaluation metrics, it is also important to carefully divide the dataset into different datasets for training, validation on a public leaderboard and also as test dataset for the final evaluation. The ratio between different classes and population should reflect the actual data distribution. As experienced during our competition, special attention should be paid to avoid data leakage for the validation and test dataset. Data leakage makes the learning algorithm generates overly optimistic score or fail entirely by taking unintended shortcuts to the results without being noticed. It can be from mistakenly include training images in the test set or even used images from the same batch in the test and training dataset. Perceptual hashing techniques to identify the same or similar images between the test set and training set and it was used by our participants during the competition. Visualization techniques such as Class Activation Maps was also used in our paper to check the visual attention of the models which can be used to identify potential data leakage issue.
Running the Contest & Online Forums
The contest ran for 100 days and had 2172 teams participating. The contest was organized by the HPA, which includes the data science team that managed the competition and analyzed the selected models, the production team that produces the images by immunofluorescence staining cells.
The HPA challenge was held on the Kaggle Competition platform.
We continually communicated with the contestants over the online forum and paid close attention to the issues and observations of the contestants. The discussions in the Kaggle forum has been helpful for sharing ideas and generating discussions about data handling, training strategies and so on. Intriguingly, we found many strategies used by the top-ranking teams are from or inspired the discussions in the forum. For example, it covers how to get external training data from the HPA website, splitting validation dataset with multi-label stratification, and there are also open notebook kernels and baseline models which helps participants quickly get started with our dataset.
Winners and Final Analyses
After the competition was closed, we teamed up with 9 teams that represented a wide range of models in both complexity and strategies used. These included the winner, top-ranking teams and a few further down the list. This diversity helps us to understand which models perform best at this task of multilabel image classification. We lucked out by having wonderful collaborators in our top-ranking teams, especially the one-man team bestfitting, who won our competition and is currently the #1 Kaggler in the world (https://www.kaggle.com/rankings). He has been actively working with us after the competition to perform ablation study and model visualization to understand more about his winning solution.

bestfitting, a Kaggle competition grandmaster, won our competition
Interestingly, we later found that the “metric learning” part of his model boosts the score unintentionally mainly works by detecting images from the same sample. Nevertheless, the metric learning and many other winning strategies generated in our challenge has been used by many kagglers for other competitions. We also believe that the winning models can be used for transfer learning, and our unique HPA Cell Atlas dataset can be used as a benchmark dataset for developing new models.




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in